Looking to use LLMs to unlock productivity in your company? Managing data permissions will accelerate value

Initially, AI was exclusive to technologically advanced businesses. However, the introduction of Large Language Models (LLMs) has accelerated the broad applicability of AI models. This necessitates the development of an AI strategy for all companies to maintain competitiveness within their respective industries.
Every industry today is being disrupted by the usage of LLMs. Companies are able to offer more competitively priced products with with higher margins by using AI and LLMs to reduce cost and increase productivity. Companies that dont are simply being left behind.
What are different industries doing?
In the past, numerous industry applications mandated the training of specific models using extensive labeled datasets. However, this is no longer the prevailing paradigm. Large Language Models (LLMs) such as ChatGPT now offer out-of-the-box functionality, which can be further enhanced through diverse tactics, yielding substantial improvements in productivity. Every industry has found areas that can be automated, improved or removed with the advent of LLMs, such as:
Document Automation in Law:
LLMs are employed to automate document creation, summarisation, and extraction. For instance, a company may use LLMs to generate contracts by connecting to customer and internal business data.
HR Process Automation in Recruiting:
LLMs are applied in human resources for tasks like resume screening, initial candidate communication, and answering frequently asked HR-related questions. This enhances the efficiency of HR processes and frees up time for more strategic activities.
Knowledge Base Management in Software:
LLMs can assist in the creation and maintenance of knowledge bases within organisations. They can help summarise and categorise information, making it easier for employees to access relevant data quickly.
Risk Auditing in Insurance:
LLMs are utilised for automating compliance checks within workflows. They can analyse documents, contracts, or policies to ensure adherence to regulatory requirements, saving time and reducing the risk of oversights.
Data Entry and Form Filling in Finance:
LLMs can automate data entry tasks by generating responses based on natural language prompts. This is useful in scenarios where repetitive form-filling or data input is required particularly where reducing input error in spaces like loan origination can create large cost savings.
McKinsey has done a deep anlaysis of what types of application businesses are building and found that each of these applications have a shared solution architecture:
Safe and secure access to an LLM (LLM Layer)
Connection to business and customer information that has complex permissions. (Data Layer)
Prompt Engineering and business logic layer (Chatbot Layer)
The ability to see what is happening within the application (monitoring and reporting Layer)
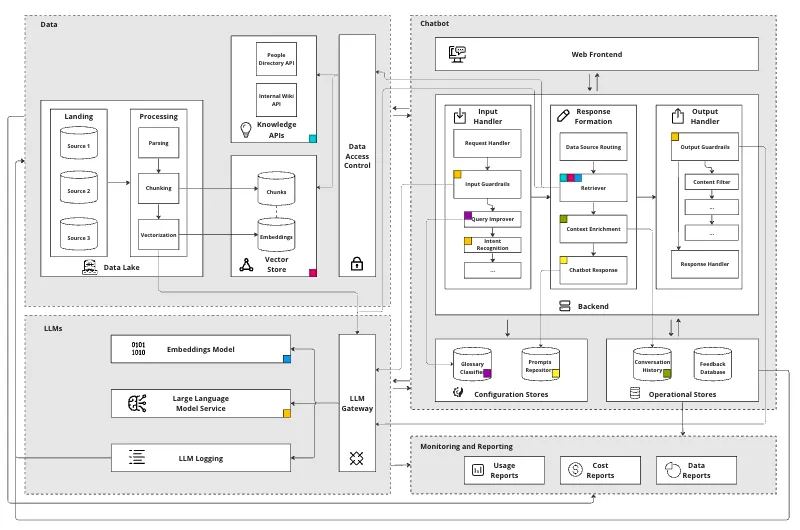
A solution architecture of the complexity of AI applications with business context - https://mlops.community/how-to-build-a-knowledge-assistant-at-scale/
Connection to business data is key to value creation
The core value of a business is in the intellectual property that is secured behind data permissions in a variety of tools (Confluence, Sharepoint, Gdrive, Salesforce all have different permission models). While generalisable LLMs are extremely powerful, context about how a business operates, their processes and their customers are vital to solve problems. Business-specific knowledge ensures that the LLM understands and generates content that is accurate and relevant to the industry, domain, or business context. This is crucial for providing users with meaningful and contextually appropriate information, and creating systems that can make decisions for internal use cases.
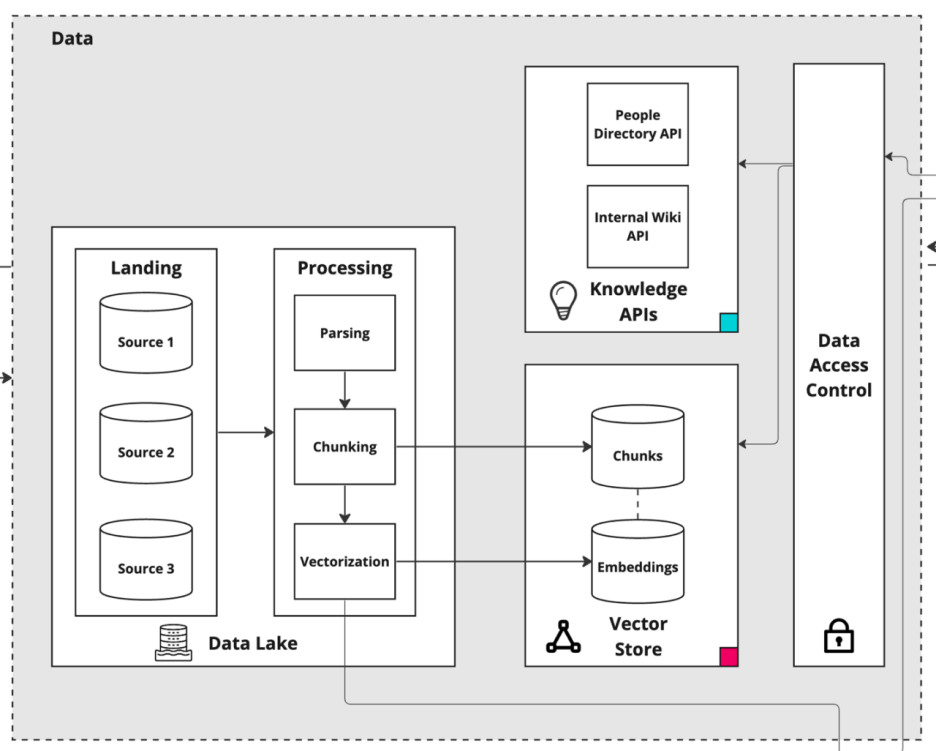
The data layer to a modern AI application- https://mlops.community/how-to-build-a-knowledge-assistant-at-scale/
The more information that an AI application can access the better answer, documents, action and decisions it can generate. However increasing the amount of information that a given application can access also increases the risk that the wrong information goes to the wrong person.
Trying to understand permissions is hard and doesn’t scale
Information in any enterprise (from 3 people to 3000) is spread across many tools. Each tool brings with it its own permission model and different ways of looking at users. Data access control can rapidly become unwieldy, and rapidly begins to block projects.
Some tools have the concept of a viewer, an admin, a super user, a commentator while other tools only have the concept of a user. When an AI application needs to access this business information, the question immediately arises: who is this AI and what should they have access to?
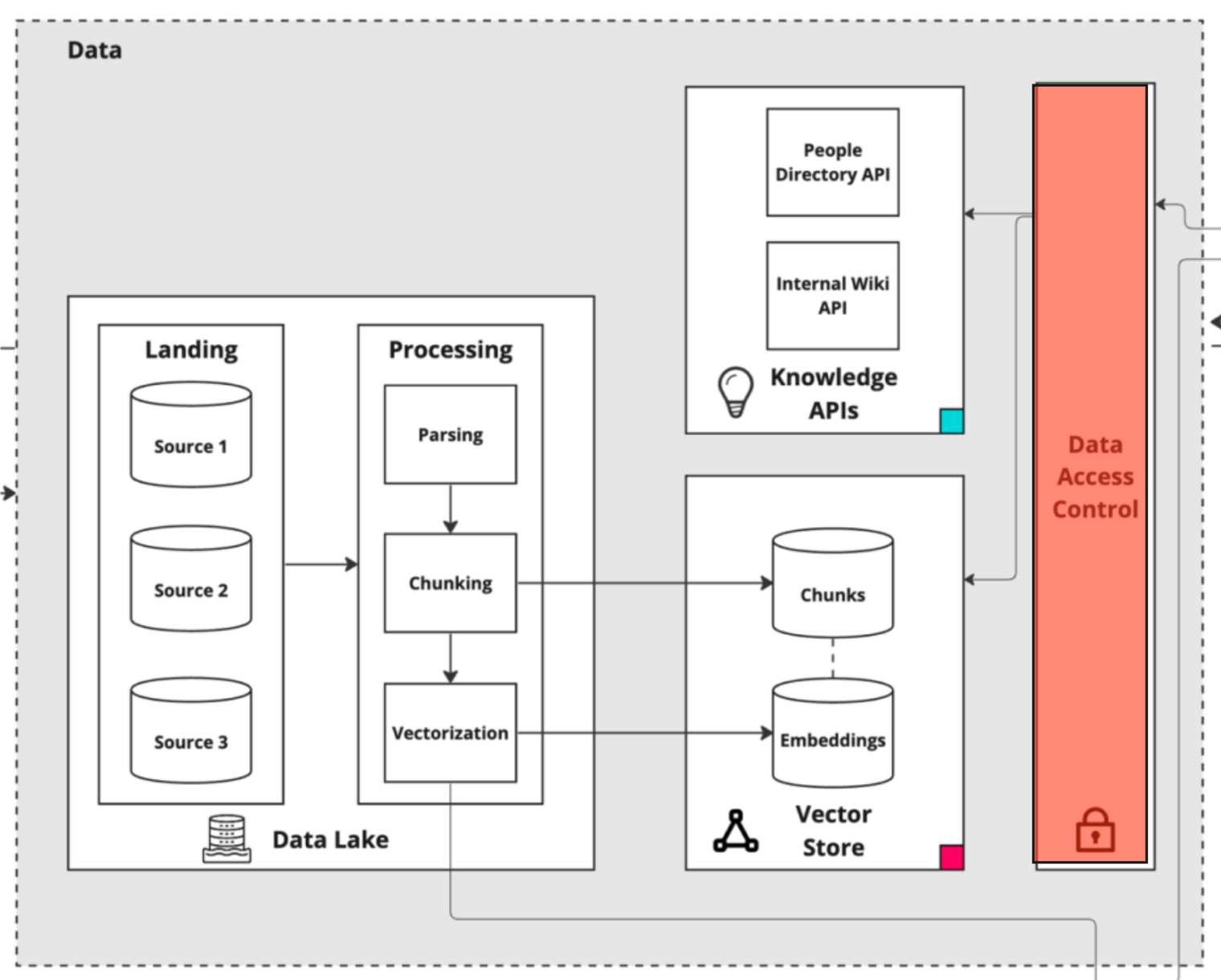
This Data Access Control Layer creates a decoupling from the source permissions, creating a threat vector - https://mlops.community/how-to-build-a-knowledge-assistant-at-scale/
Inheriting the user
When AI performs actions, it should always perform those actions on behalf of a given person or user. This means that when applications function they need to inherit the same permissions as the user that is utilising the application. But there is a problem: how do I understand what information a given user can access if all the tools have such varied permission models?
Many tools attempt to do this by crawling the tools for their data and their permission. This process involves a software service going to different tools and checking if changes have been made and pulling those changes into a seperate data base. It is a simple implementation, but it is expensive and insecure. Every second between these checks is a threat vector to leak information to the wrong person with the wrong permission.
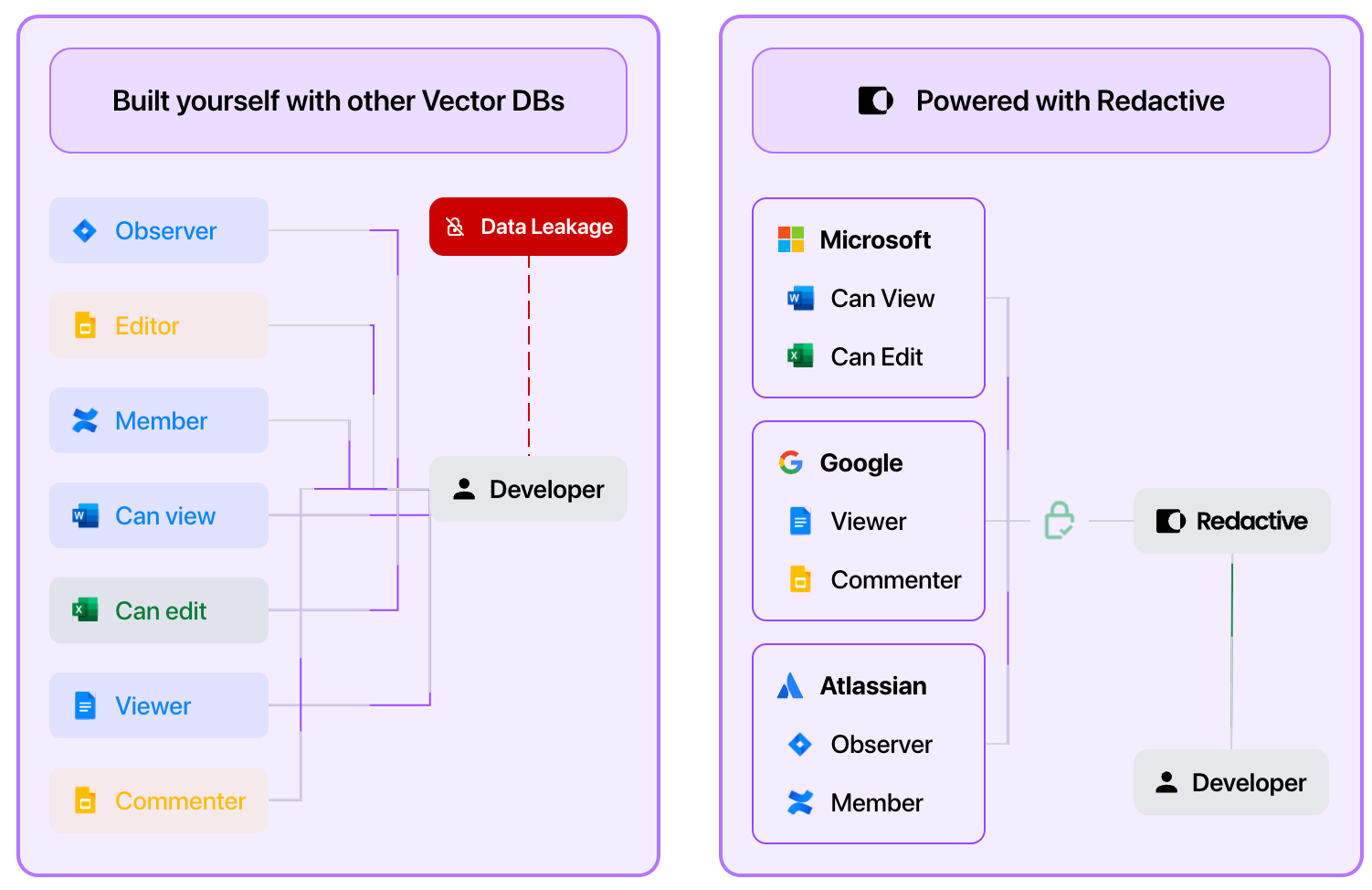
Managing permissions with vectorDBs always create a missmatch in permissions, Redactive’s at-query-time permission check resolves this issue.
The more valuable the data the bigger the problem
The most important information in a business is often only accessible by trusted people, and as businesses get larger and these permissioned datasets only increase. They exist everywhere: Confluence, Slack, Teams, email, Salesforce and custom databases - the list goes on. With more data comes more permissions, more complexity -once you throw additional web services into the mix that might be managed by a company: the average organisation ends up 7.7K groups, and any individual engineer may already be part of hundreds or even thousands of groups, each with overlapping definitions of access (thanks to Rak Garg - Identity Crisis: The Biggest Prize in Security).
A permission aware future.
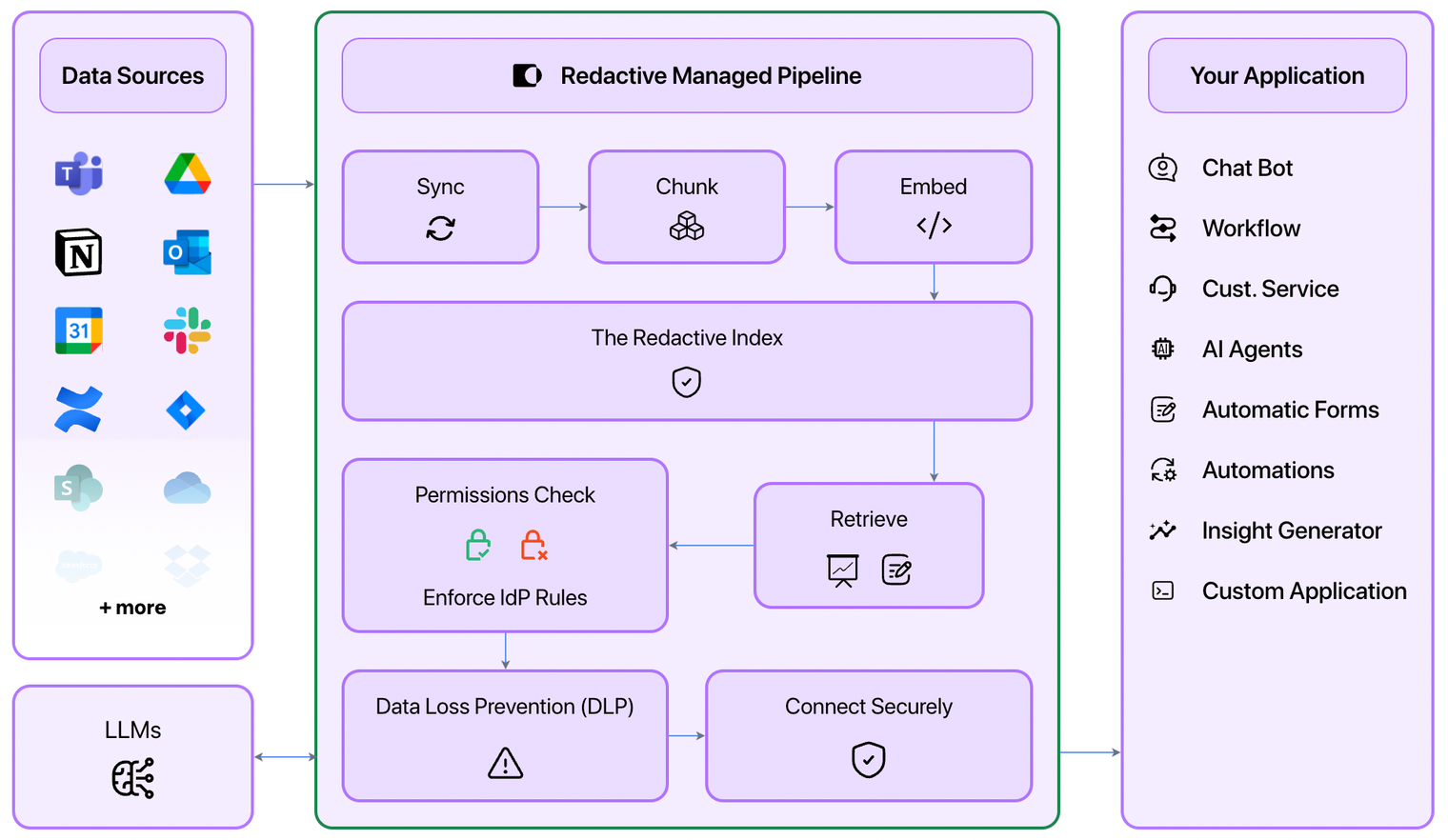
The Redactive Managed Pipeline resolves much of the complexity of connecting your application to business data
Accessing information for novel AI applications is too important to be blocked by complexity. Redactive solves the data access problems without duplicating your information or normalising permissions. Power your AI applications while respecting the permissions of the data where it resides in the source tool. If you are looking to connect your AI applications to business data, please contact me: [email protected]
Forget about chunking, embedding and Vector Databases. Redactive's managed RAG pipelines make it easy to access the context you need via our SDK.